Druid cluster architecture¶
A Druid cluster consists of different types of nodes and each node type is designed to perform a specific set of things:
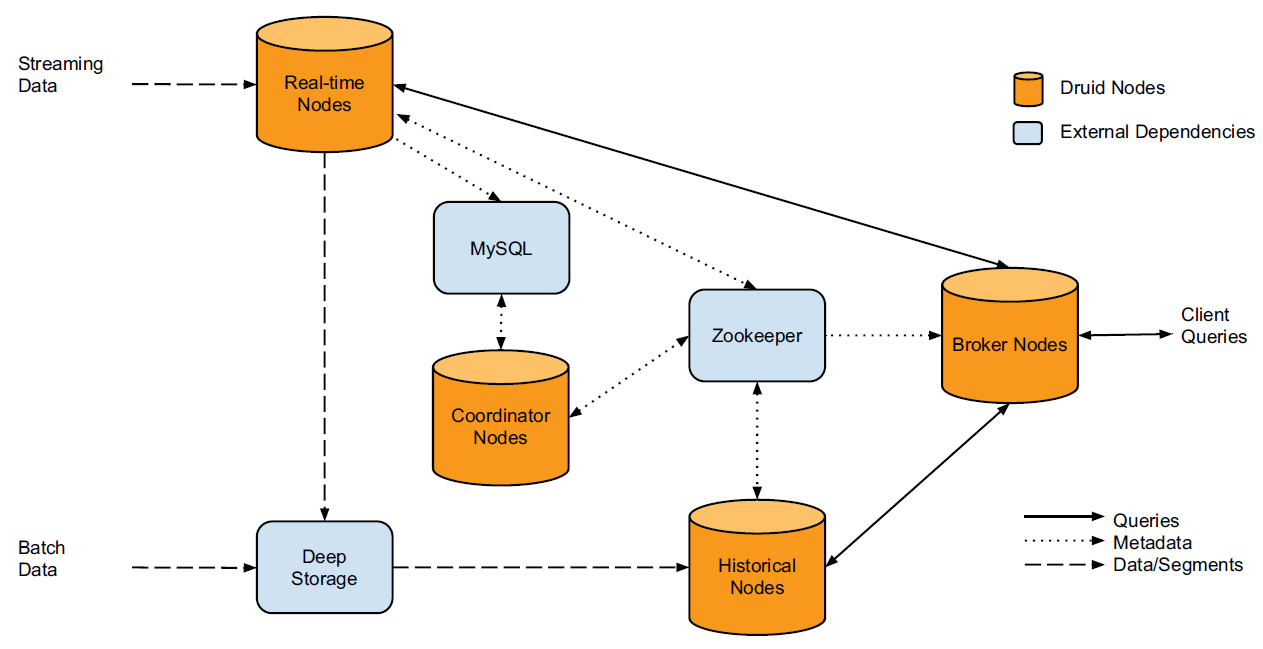
Real-time nodes¶
Real-time nodes function to ingest and query event streams. The nodes are only concerned with events for some small time range and periodically hand them off to the deep storage in the following steps:
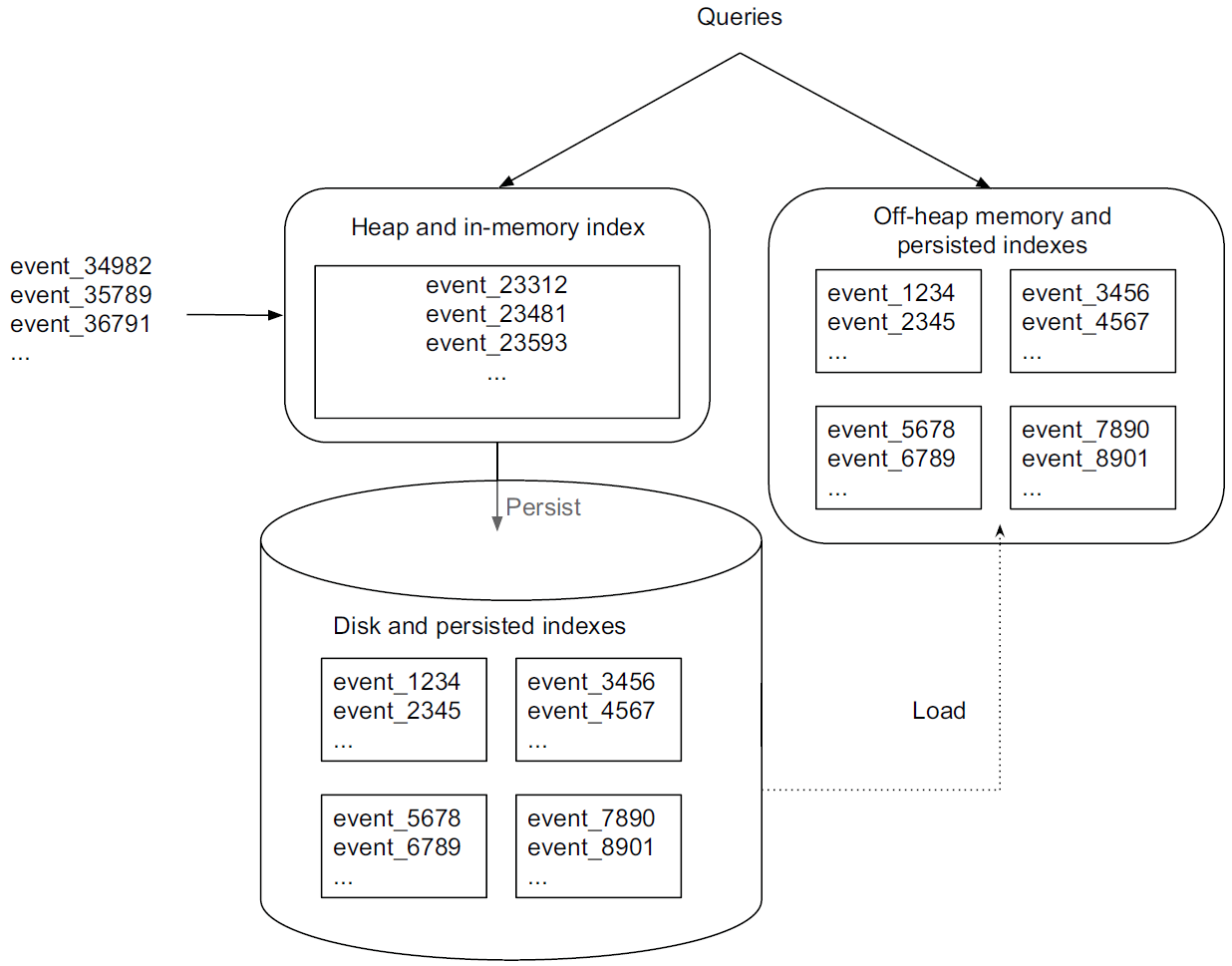
Source: Druid: A Real-time Analytical Data Store
- Incoming events are indexed in memory and immediately become available for querying.
- The in-memory data is regularly persisted to disk and converted into an immutable, columnar storage format.
- The persisted data is loaded into off-heap memory to be still queryable.
- On a periodic basis, the persisted indexes are merged together to form a “segment” of data and then get handed off to deep storage.
In this way, all events ingested into real-time nodes, regardless before or after persisted, are present in memory (either on- or off-heap) and thus can be queried (queries hit both the in-memory and persisted indexes). This functionality of real-time nodes enables Druid to conduct real-time data ingestion meaning that events can be queried almost as soon as they occur. In addition, there is no data loss during these steps. In addition, there is no data loss during these steps.
Real-time nodes announce their online state and the data they serve in Zookeeper (see External dependencies) for the purpose of coordination with the rest of the Druid cluster.
Historical nodes¶
Historical nodes function to load and serve the immutable blocks of data (segments) created by real-time nodes. These nodes download immutable segments locally from the deep storage and serve queries over those segments (e.g., data aggregation/filtering). The nodes are operationally simple based on a shared-nothing architecture; they have no single point of contention and simply load, drop, and serve segments as instructed by Zookeeper.
A historical node’s process of serving a query is as follows:
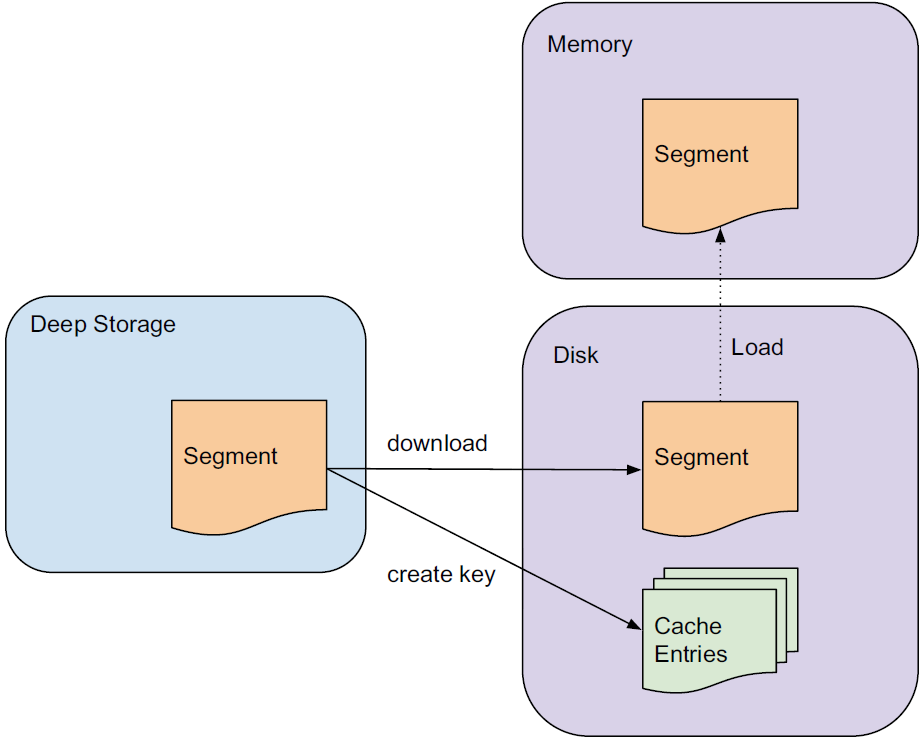
Source: Druid: A Real-time Analytical Data Store
Once a query is received, the historical node first checks a local cache that maintains information about what segments already exist on the node. If information about a segment in question is not present in the cache, the node will proceed to download the segment from deep storage. On the completion of the processing, the segment is announced in Zookeeper to become queryable and the node performs the requested query on the segment.
Historical nodes can support read consistency because they only deal with immutable data. Immutable data blocks also enable a simple parallelization model: historical nodes can concurrently scan and aggregate immutable blocks without blocking.
Similar to real-time nodes, historical nodes announce their online state and the data they are serving in Zookeeper.
Broker nodes¶
Broker nodes understand the metadata published in Zookeeper about what segments are queryable and where those segments are located. Broker nodes route incoming queries such that the queries hit the right historical or real-time nodes. Broker nodes also merge partial results from historical and real-time nodes before returning a final consolidated result to the caller.
Broker nodes use a cache for resource efficiency as follows:

Source: Druid: A Real-time Analytical Data Store
Once a broker node receives a query involving a number of segments, it checks for segments already existing in the cache. For any segments absent in the cache, the broker node will forward the query to the correct historical and real-time nodes. Once historical nodes return their results, the broker will cache these results on a per-segment basis for future use. Real-time data is never cached and hence requests for real-time data will always be forwarded to real-time nodes. Since real-time data is perpetually changing, caching the results is unreliable.
Coordinator nodes¶
Coordinator nodes are primarily in charge of data management and distribution on historical nodes. The coordinator nodes determine which historical nodes perform queries on which segments and tell them to load new data, drop outdated data, replicate data, and move data to load balance. This enables fast, efficient, and stable data processing in a distributed group of historical nodes.
As with all Druid nodes, coordinator nodes maintain a Zookeeper connection for current cluster information. Coordinator nodes also maintain a connection to a MySQL database that contains additional operational parameters and configurations, including a rule table that governs how segments are created, destroyed, and replicated in the cluster.
Coordinator nodes undergo a leader-election process that determines a single node that runs the coordinator functionality. The remaining coordinator nodes act as redundant backups.
External dependencies¶
Druid has a couple of external dependencies for cluster operations.
- Zookeeper: Druid relies on Zookeeper for intra-cluster communication.
- Metadata storage: Druid relies on a metadata storage to store metadata about segments and configuration. MySQL and PostgreSQL are popular metadata stores for production.
- Deep storage: Deep storage acts as a permanent backup of segments. Services that create segments upload segments to deep storage and historical nodes download segments from deep storage. S3 and HDFS are popular deep storages.
High availability characteristics¶
Druid is designed to have no single point of failure. The different node types operate fairly independent of each other and there is minimal interaction among them. Hence, intra-cluster communication failures have minimal impact on data availability. To run a highly available Druid cluster, you should have at least two nodes of every node type running.
Architecture extensibility¶
Druid features a modular, extensible platform that allows various external modules to be added to its basic architecture. An example of how Druid’s architecture can be extended with modules is shown below:
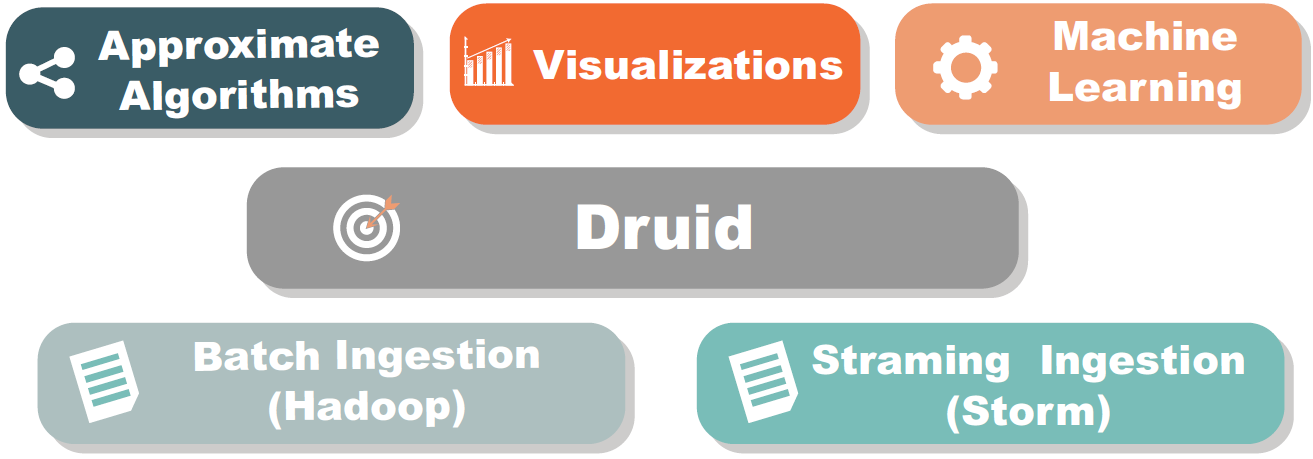
Source: MetaMarkets - Introduction to Druid by Fangjin Yang
Metatron, an end-to-end business intelligence solution to be introduced in this paper, was also built by adding various modules to the Druid engine.